
You're Not Behind! The Architecture Underneath AI Is Older Than You Think.

Expanding on my video from today.
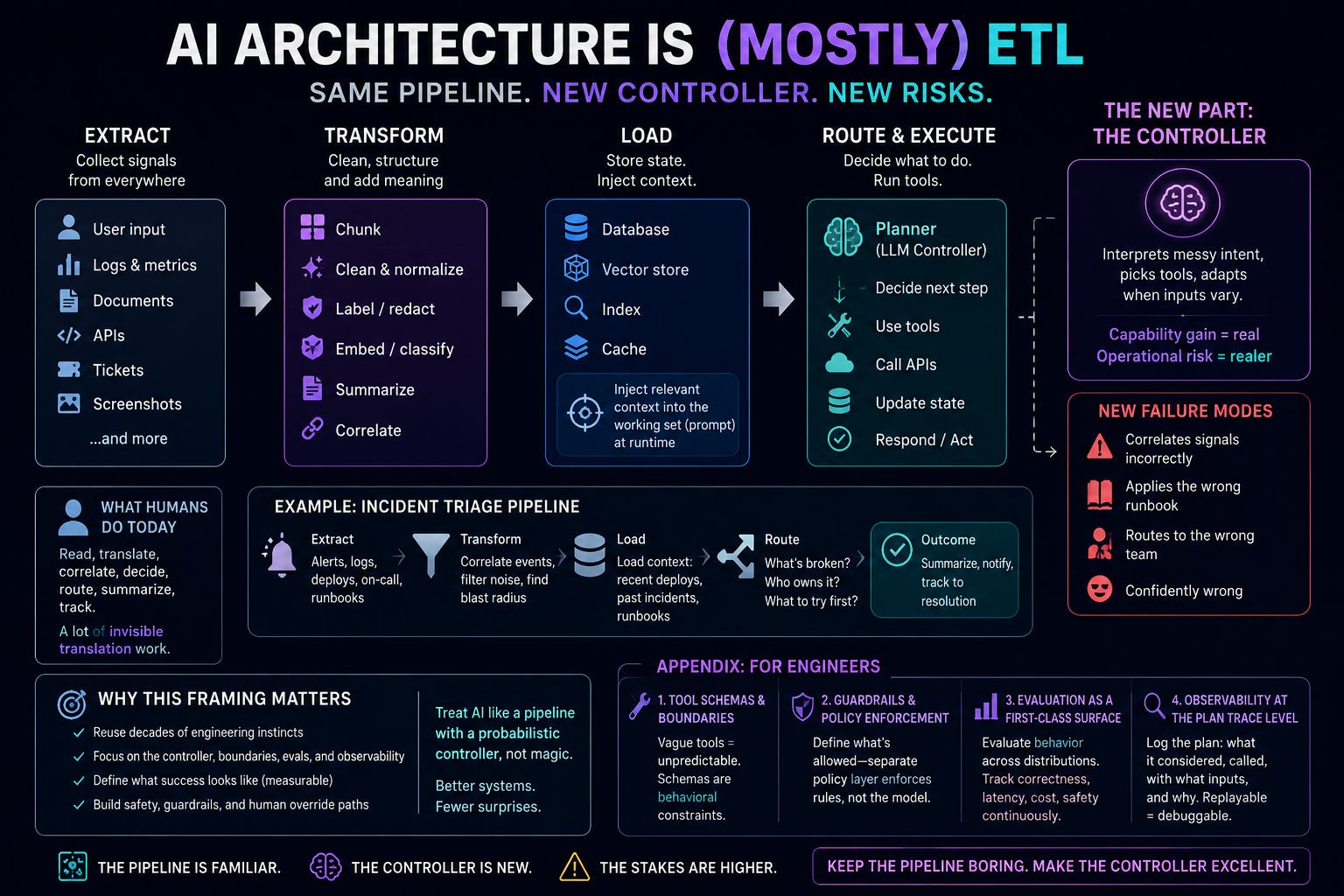
The claim that annoys people is simple: a lot of modern AI architecture is ETL with a language model on top. People hear this and assume it is dismissive. This is a simple way to see the system clearly so you can build it correctly.
What ETL Means In This Context
When most teams say ETL they picture batch jobs moving data into a warehouse which a narrow view. ETL in the AI world means the broad pattern of moving information through a system: you pull signals in, reshape them, join them with context and push them to the next step. If you have built event pipelines, workflow engines, microservice integrations, feature stores, recommendation pipelines or search and retrieval layers, you have already built the skeleton of what most agentic architecture diagrams describe. If you pay attention closely, the labels changed but the data flow didn’t go anywhere.
One clarification worth making explicit: I am using ETL as shorthand for pipeline-shaped systems, not as a claim that everything is a warehouse job.
The Modern AI Version of the Same Flow
Here is the same pattern with modern labels.
Extract
You collect user input, logs, documents, API responses, tickets, screenshots and whatever else exists in the environment. This is the same old ingestion but the sources are a littlle messier and more varied while the operation is the same.
Transform
You chunk, clean, normalize, label, redact and structure while sometimes embedding. Sometimes you classify. Sometimes you summarize. In the end, it is still transformation regardless of what you call it.
Load
You store state that future steps depend on. This might be a database, an index, a vector store or a cache. In LLM systems a critical part of load is injecting context directly into the working set, meaning you are loading relevant state into the prompt at runtime rather than persisting it to disk. The architecture is established and the runtime surface is new.
Route and Execute
You decide what to do next and run tools. This step used to be code and rules; however, now it can be a planner. In production you still need deterministic constraints around the planner.
Remember → The planner expands what is possible while constraints define what is allowed.
What Is Actually New
The novelty is the controller and the pipeline itself is not new.
A language model changes the control plane because it can interpret messy intent, pick among tools, propose steps and adapt when inputs look different from what you expected. This is the real capability gain and it is also the source of the operational risk.
Think about how an enterprise handles a production incident today.
An alert fires. Someone reads it, pulls context from 3+ different systems, figures out what is actually broken versus what is noise, routes it to the right team, summarizes the situation for the on-call engineer and tracks it through to resolution. At every step a human is translating ambiguity while deciding what matters, what to ignore and who needs to know. The translation work is invisible in most org charts but it is where a significant amount of time goes during an incident.
An agentic incident triage system runs the same underlying flow. It extracts signals from monitoring tools, error logs, deployment history and on-call schedules. Then it transforms the raw signals by correlating events, filtering noise and identifying the blast radius. After that, it loads relevant context, recent deploys, past incidents, runbook entries, into the working set so the next step has what it needs. Finally it routes: “is this a database issue or an application issue”, “which team owns it”, “what does the runbook say to try first?” and so on.
The execution pattern is nearly identical to what a senior engineer does manually. The difference is that a language model can do the translation step across unstructured and inconsistent inputs without requiring every upstream system to speak the same schema.
Which is why new failure modes appear. The model can correlate signals incorrectly and sound confident doing it. It can retrieve the right runbook entry and apply it to the wrong situation. It can route to the right team based on a hallucinated diagnosis. Classic ETL does not do this because a deterministic pipeline either works or throws an error. Meanwhile, a probabilistic controller like an agent can fail silently and fluently which is a meaningfully different operational problem.
Why Does This Framing Matter?
If you treat modern AI like alien magic and focus only on “speed” you will build the wrong thing. You build demos, skip guardrails, do not instrument the boundaries and never define what success actually looks like in measurable terms.
If you treat modern AI like a pipeline with a probabilistic controller you ask the right questions: what is the source of truth?, what is derived state?, what actions are allowed?, what do we log?, what do we evaluate? and what is the human override path when the controller gets it wrong?
The incident triage example makes the stakes clearly visible.
An agentic system that mis-routes a severity one incident or confidently summarizes the wrong root cause does not only create a bad user experience. It extends downtime and erodes trust in the tooling. In other words, the data flow underneath is established but the failure conditions are not.
Closing
“Mostly ETL” is not intended to be vague or an insult. It is a map that lets you reuse decades of engineering and product development instincts and focus your energy where it actually belongs: on the controller, the safety boundaries, the evaluation layer and the observability that tells you when the system is drifting.
If you’ve lived in these spaces remember that YOU ARE NOT BEHIND
You are watching established systems patterns be exposed via new interfaces with a new category of failure modes that do not announce themselves.
The trick is to keep the pipeline boring which does not mean “easy”. It means well understood, well instrumented and not the place where you want surprises.
Learn more about the controller because is where the work actually is.
Appendix: For the Engineers in the Room
In a deterministic system, complexity lives in the code paths. You can read the logic, trace the execution and write tests that confirm expected behavior. When something breaks you have a stack trace and typically the failure is loud.
In an agentic system, complexity migrates into 4 areas that most engineering organizations do not have mature practices around yet.
Tool schemas and action boundaries. The model’s behavior is partly a function of how you define the tools available to it. Vague tool descriptions produce unpredictable tool selection. Overlapping tool capabilities create ambiguous routing. In the incident triage context, if your “search runbook” tool and your “escalate to on-call” tool have poorly defined boundaries, the planner will make judgment calls you did not anticipate. The schema is not only documentation and instead a behavioral constraint. You must treat it like one!
Guardrails and policy enforcement. Deterministic systems enforce rules in code. Agentic systems need a separate policy layer that defines what actions are permissible regardless of what the planner decides. In incident triage this means explicit rules around when the system can page someone versus when it must wait for human confirmation, what it is allowed to write versus what it can only read and what constitutes an action that requires escalation before execution. The constraints do not emerge from the model so you have to design and enforce them explicitly!
Evaluation as a first-class engineering surface. In a deterministic pipeline you test inputs and outputs. In an agentic system you evaluate behavior across a distribution of inputs, because the same input can produce different outputs across runs and because correctness is often contextual rather than binary. For incident triage this means building an eval set of historical incidents with known correct diagnoses and resolutions, running the system against them regularly and tracking correctness, latency, cost and safety as ongoing metrics rather than one-time checks. Evals are not QA. They are the feedback loop that tells you whether the system is still doing what you think it is doing and typically tied to a metric or a dimension of a greater metric.
Observability at the plan trace level. Standard application logging tells you what happened at the infrastructure layer. Agentic systems require logging at the decision layer: what did the planner consider?, what tools did it call?, in what order?, with what inputs and what did it do with the outputs? and so on. Without plan trace observability you are debugging a probabilistic system with deterministic tools, which means you will spend a lot of time guessing. In a production incident triage system, the ability to replay exactly what the agent saw and decided during a past incident is not a nice-to-have. It is the only way you can identify drift, catch prompt injection attempts and build the institutional knowledge to improve the system over time.
The cross cutting concern across all 4 is the same: the engineering work that used to live in explicit code paths now lives in schemas, policies, evals and observability infrastructure. It’s still a lot of work because most engineering teams do not have mature practices around schemas, evals, policy enforcement and plan-level observability.