
LLM failover is not cloud failover

This started as a throwaway reliability question and turned into an uncomfortable realization.
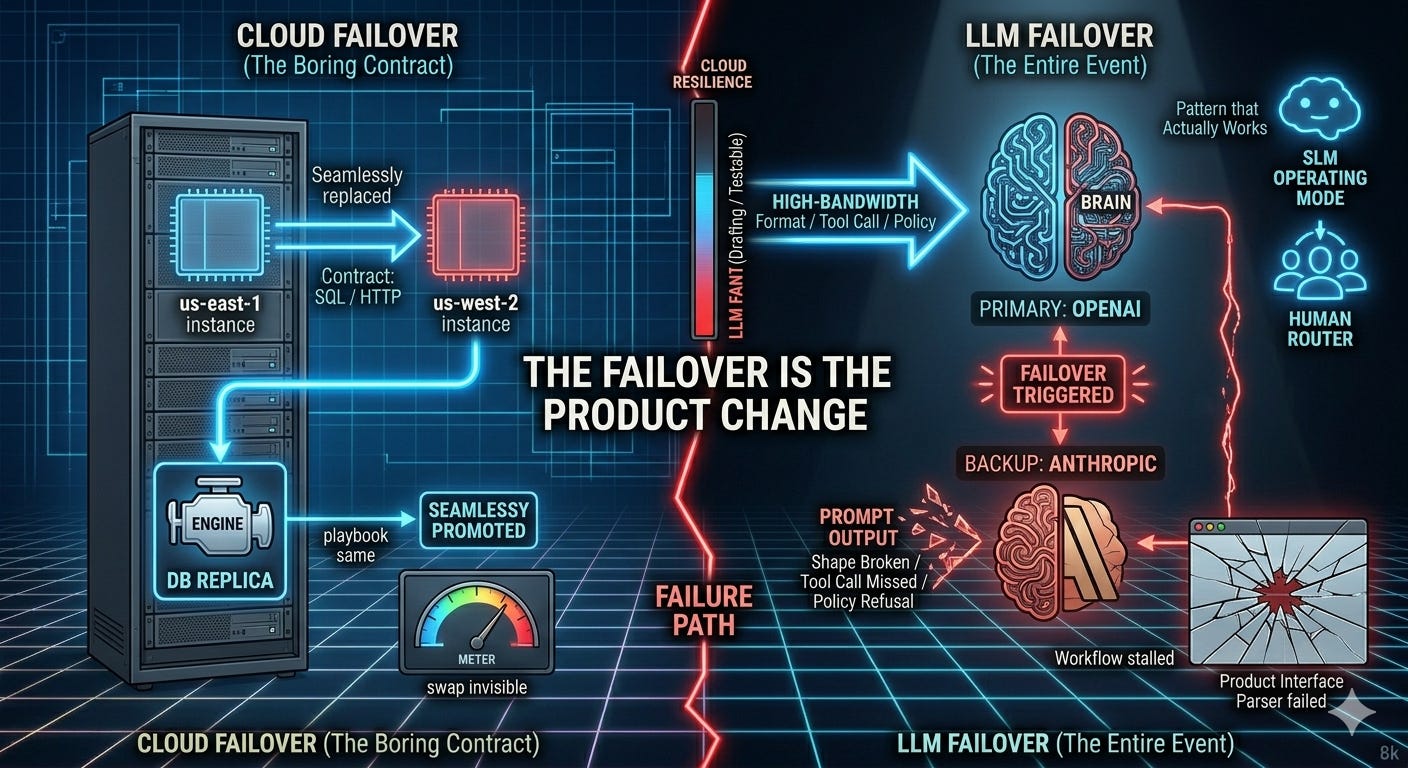
People keep saying “we’ll just fail over from OpenAI to Anthropic” the way they say “we’ll fail over from us-east-1 to us-west-2.”
It sounds smart and responsible. Unfortunately, it also hides the work because LLM failover isn’t a vendor decision.
Here’s the moment it clicked for me: in a Slack thread, someone politely challenged the word train by stating “you’re not training OpenAI or Anthropic, you probably mean RAG or fine-tuning.”Which is a fair and accurate correction. It’s also where conversations about LLM reliability often stop: retries, RAG, maybe a router and a vague sense that you’ve handled it.
Once an LLM is inside a workflow that has real product consequences, the question stops being “can Model B give a decent answer?” and becomes “can Model B safely perform the same job inside my system?”
Cloud failover works because the contract is boring
Cloud failover works because the playbook stay the same.
If my database replica is promoted, it still speaks SQL.
If my instance is replaced, my code still runs.
If my CDN flips, the HTTP semantics don’t change.
The entire system is designed around the idea that the provider swap is mostly invisible.
LLMs are the opposite because the provider swap is the whole event.
With LLMs, “behaves differently” doesn’t just mean “answers are a little worse.” It can mean the workflow stops working:
it returns a different output shape and your parser breaks
it calls different tools (or none) and the system stalls
it refuses where the primary would proceed (or proceeds where the primary would refuse)
The risk isn’t only degraded quality. It’s broken product behavior.
What breaks when you swap models
“Just switch providers” assumes the model is interchangeable.
In practice, the model is sitting inside a workflow that expects very specific behaviors.
When you swap models, the failure mode is that the workflow itself can break.
Here’s what the system is depending on:
Format: does it return the exact JSON your code expects, every time?
Tools: does it call the right tool, with valid arguments, at the right moment?
Error handling: when a tool fails, does it retry/escalate—or make something up?
Policy: does it stop when it should stop, and proceed when it should proceed?
If these shift then you didn’t “fail over.” You changed how the product behaves.
“Isn’t this just RAG?”
RAG is just a way to hand a model your docs which helps with knowledge and context but it doesn’t guarantee behavior.
If you swap models but keep the same retrieval then you still haven’t answered the question that matters in production:
“Will the backup model reliably do the job—same format, same tools, same stop/go decisions?”
RAG can make the backup model less wrong but, unfortunately, it can’t make it interchangeable.
The expensive part is keeping the backup path warm
Failover only exists if the backup path is already wired into the product and regularly used; otherwise, it’s a dead switch.
In reality everything keeps moving:
models update
prompts drift
tools and schemas change
If you don’t run the backup path in real life routinely then it will be broken the day you need it.
Retries and routers are not a reliability strategy
Retries help when the model is fine and the network is flaky but they don’t help when the model does the wrong thing.
For example, if you need a strict JSON shape, a specific tool call or a “stop/go” decision then retrying just gives you another roll of the dice.
Routers are similar: they can route around outages and rate limits but they can’t guarantee the substitute model behaves the same inside your workflow.
Fail over to an operating mode (often an SLM) is a pattern that actually works
What tends to work better is failing over to a simpler mode you can reliably trust.
This looks like a smaller model (or even rules/templates) that only handles the “keep the lights on” parts:
produce valid structured output
pick tools and fill arguments
extract the few fields you need
route uncertain/risky cases to a human
It’s boring and less magical but it’s testable and reliable.
The 3 choices (without the fantasy option)
If you ship an LLM on a critical path, you’ve got 3 honest options:
Accept downtime and make it explicit in the product.
Build a degraded mode that still works.
Maintain a real second path and keep it healthy.
There isn’t a free option where you do none of it and still call it “resilient.”
The real question underneath
When a team says “we need failover,” what they’re really deciding is whether this is a feature or part of the product’s operating model.
The “brain” is part of the product now. When it changes, the product changes.